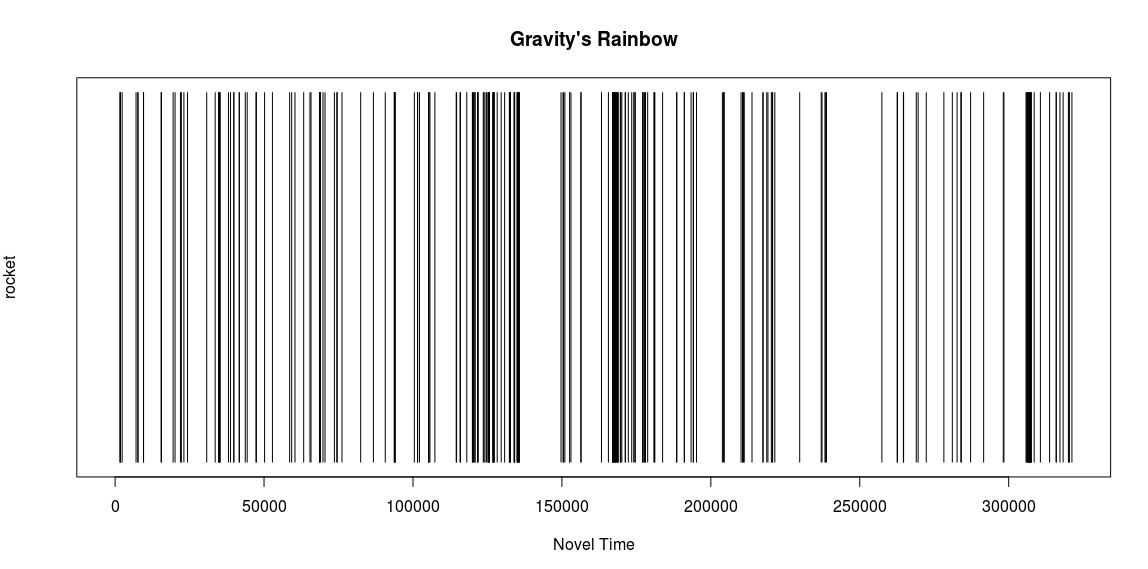
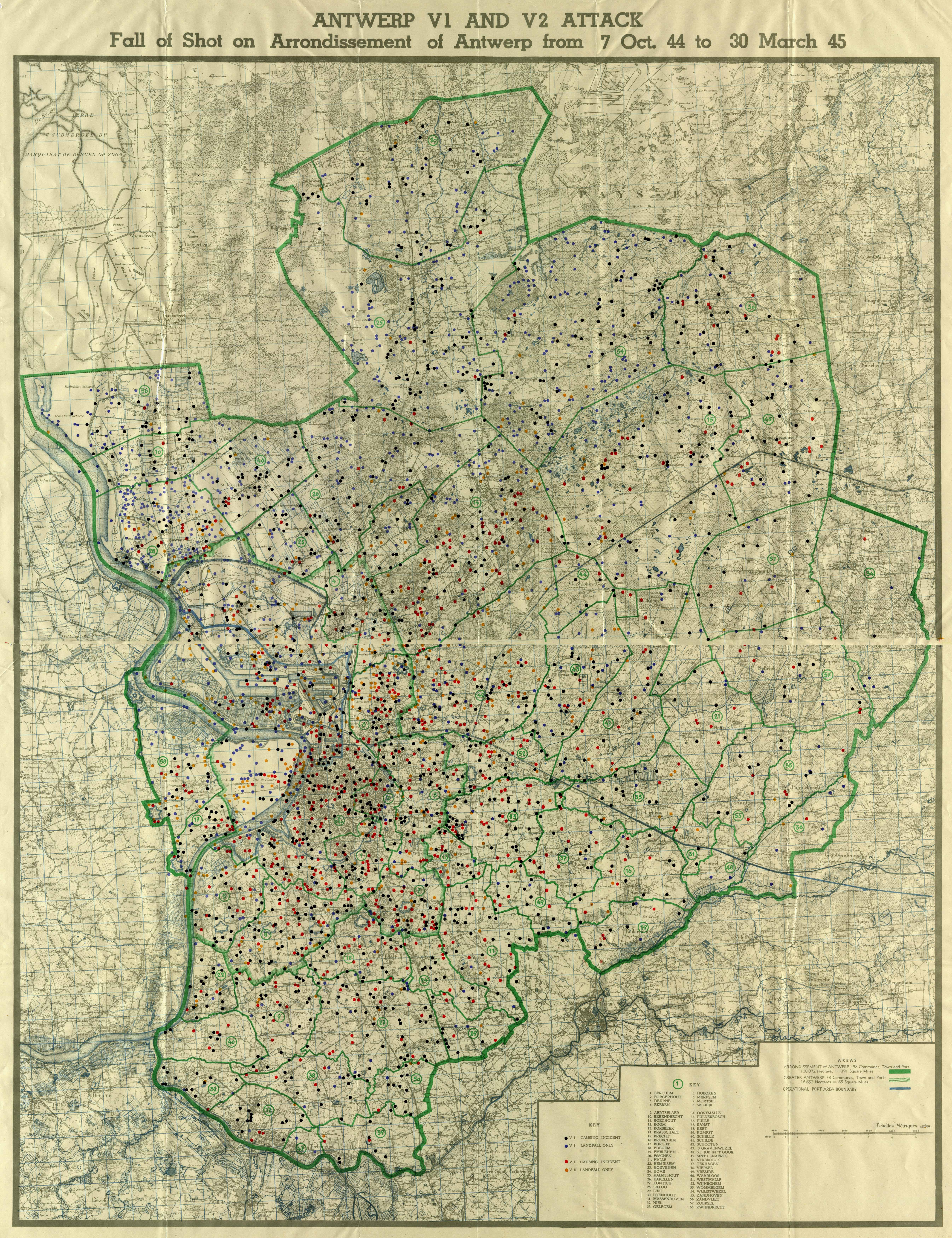
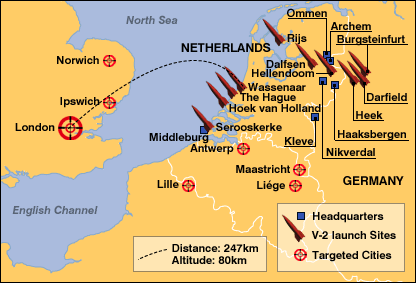
I want to go ahead and ask, right off the bat, that any scholar/researcher that has found this blog post: I’d like to invite you to join my alpha testers on my Gentle Introductions Resource: https://boiling-wildwood-9939.herokuapp.com/
It has been quite a while since I posted on this blog, and looking at it, I believe there is a clear distinction from the posts I’d been writing when I had been in a class (this blog began as a required supplement to a DH course), and the posts I was trying to write while spending the bulk of my time solidifying the foundations of my MALS thesis.
Looking at my lasts two posts, it strikes me as rather funny that I have now failed at picking a traditional piece of literature as a foundational aspect of my thesis, nor have I truly mastered Python. Instead, shortly after writing the last post I had found myself incredibly frustrated with Python. I never could get it to deploy correctly on Heroku (the platform I’ve used for deploying apps). As a result, I got nervous… very nervous. I started pouring through Christopher Marlowe’s Faust, believing that I could simply write a traditional paper on some British literature and perhaps “mark it up nice” with some Python syntax: easy enough but disappointing. But what could I do?! Time was now of the essence, summer was over!
Then a friend of mine suggested I “try Ruby.”
Believe me, I had no interest in looking at another computer language. I had already spent so much time with R and with Python… another languge? I felt the school semester had already started, I had spent all summer learning Git, and Python, and PyGame, there was Django… I was NOT going to jump into another language… but then I saw this:

Figure 1: _why’s Poignant Guide to Ruby
This online book made me so excited to try learning a language. I had been so tired of montanous manual-speak I found in many Python manuals, and here was this pseudo graphic novel that was just so fun; So appealing. I decided, because I really wanted to savor this book, that I would take a couple hours to go through a more direct tutorial first. I found one completely by accident, The Rails Tutorial by Michael Hartl:

Figure 2: Michael Hartl’s Rails Tutorial
This all took place in a day mind you, but two weeks later I had the beginnings of a working “web app” developed in Ruby using Rails. All the things I had learned while pushing my way through Python were starting to click, and now I was looking at a language far more beautiful… which might sound strange. This programming stuff begins to have an ineffable aesthetic. Here is a selection of Python Code:

Now HERE is a selection of Ruby Code:

Now, this is a subjective belief, that Ruby is a nicer code. I’m sure there are plenty of Python enthusiasts who would call it nothing but pure myth. But this is all part of the mythos of the Ruby Language, but the fact that it had such a thing that it seemed to have breathed from the moment I saw two cartoon foxes as protagonists in a book teaching a computer language.

Figure 3: from _why’s Poignant Guide to Ruby
Python, it seemed from my vantage point, was a nod to a British TV show and a practical, usable code. Ruby on the other hand seemed to have a whole slew of creatives excited about making the language itself and a community of thinkers be part and parcel.
I had started using the language in a purely trepedatious way, as if it were a curiosity during a panicked moment of procrastination, but because I had struggled with concepts that all either had direct meaning when using Ruby (Git) or could be easily transitioned from one language to the other (Django => Rails)… Ruby was this breathe of fresh air; Something new and shiny that spoke to me.
Now I think the same thing might have happened to someone that might have jumped into Ruby, not felt at home, and then discovered Python. The point I’m making with my little write up here is that it can take a lot of time and hard lessons to point one in the direction that they find most self-defining or at least relevant. Now I’m sure there is someone that learned Ruby right away, in a classroom, and is so glad they did and smirks when someone says they learned it on their own. I definitely have my share of issues when sitting down to speak with a seasoned programmer, but I think it is okay for a Digital Humanities program to encourage exploration of the field over a direct route incensed with imagined mathematical perfection when it comes to digital mediation and control over such things.
But I’m not getting on a soap box, I’m just wrapping up with the thought that perhaps it is okay to find your own path through personal filtration of a lot of information. Or anyway, whether it is or it isn’t, that is what I did. And I’m really enjoying this language. If you want to see more things I’ve done with it, here are more links:
And there are other things still in my development environment that run in my terminal, not yet on the web. I have been very productive in this language. I even received a scholarship to attend RubyConf ’13…

Figure 4: RUBYCONF 2013 logo
Don’t worry, I didn’t hose them acting like I’d been using this language forever, I confessed I was a Ruby NOOB, but the community respected a MALS researcher interested in getting thoughts about the language straight from them. It was an incredibly nice crowd, full of experts and veterans, but plenty of curious new practitioners that had found the language the same way I had: through trying to learn something new and challenging.