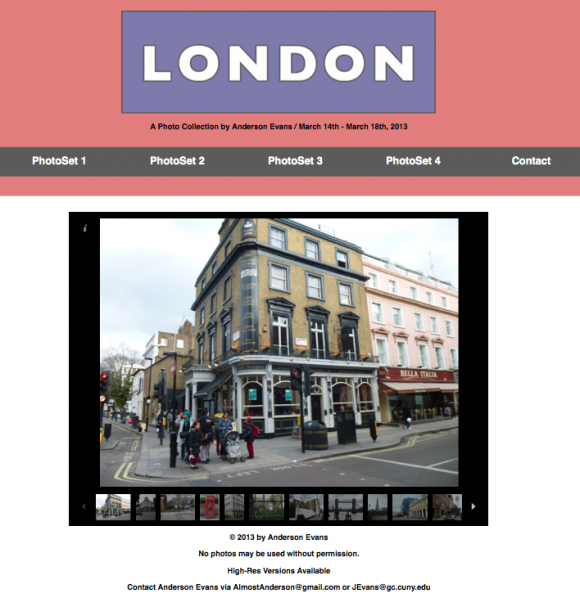
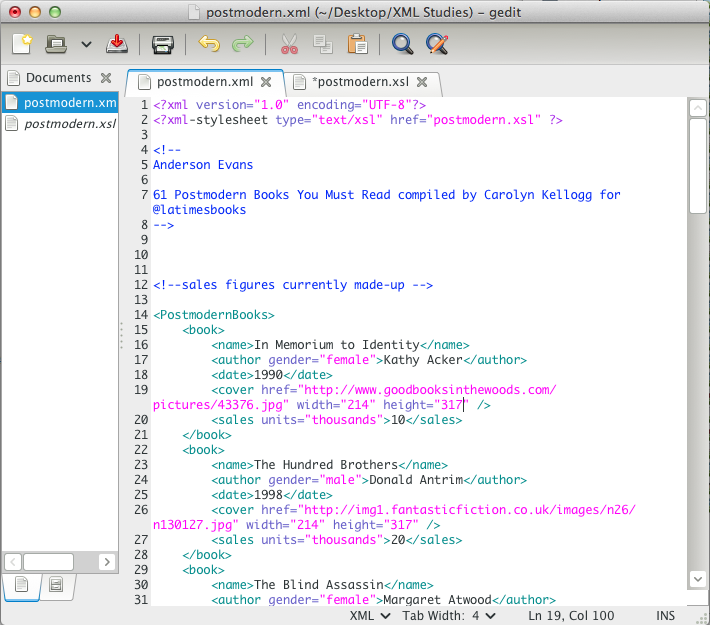
I have logged a lot of hours this semester trying to learn some things that make the concepts we’ve been discussing in our Digital Humanities classes somewhat practical. Save for the few computer science people peppered in the MALS roster, I have little doubt these steps seem dubious to the bulk of the class. Last week I attempted to write rather hefty blog post on my initial experience with XML and XSLT, but for some reason the blog post would not correctly display, and remains in draft form. I hope to fix this issue at some point.
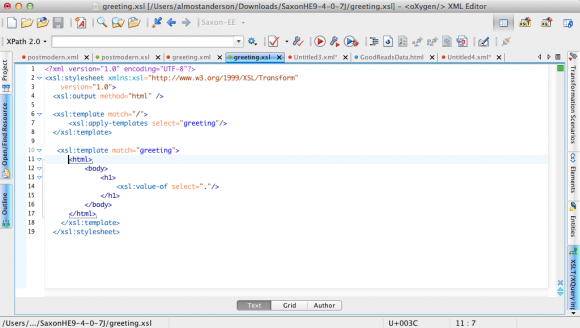
A simple XSLT stylesheet in oXygen 14.2
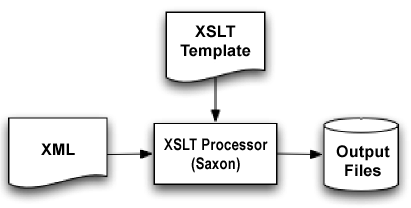
This week I attempted something somewhat more involved than strictly adding XSLT styling to a small sample of a dataset encoded with XML, and I have turned an XML file into an HTML file using an XSLT processor. What I found most difficult about this process was a combination of optimizing java on my OS X 10.8.2 machine as well as using this machine’s command line. After a long day of trying to get it right, I was finally able to execute a simple “Hello, World!” HTML file.
This image via http://today.java.net/images/2004/05/figure2.gif looks relevant enough to me!
I am currently trying to slog through an O’Reilly book on XSLT, and it suggests I utilize an XSLT processor called XALAN, which seems to have been left behind sometime in 2007. I then realized the book I was reading has a 2001 publication date, so I worry I might be learning a slightly outmoded way of doing things. While I was not able to get an archived version of XALAN up and running, I was able to configure another open source XSLT processor called SAXON to run via the terminal.

SAXON running via Terminal… It may be super tiny, but at least it isn’t Comic Sans, amIright?
I am now going to attempt to take a dataset that is significantly larger than “Hello, World!” and use XSLT to create a dataset.
Now while I explained what I did in 6 – 8 hours in a few short paragraphs, the process was far from smooth. Anyone else who is dipping their toes into these waters without a lot of swimming lessons will probably find that many of the resources they are finding seem outdated. XML seems to be something many programmers are currently trying to move beyond. Twitter’s API (Application Programming Interface) only recently went from having their data available in XML format and JSON format to strictly JSON. JSON is a format you start seeing across the board when it comes to practical uses of API, however in the Digital Humanities realm, this is not the case… or is it?
Once I started seeing the coorelation between XML’s vanishing traces and JSON’s sweeps I began searching specifically for JSON and TEI together, and found some interesting thoughts on this subject, such as:
- JSON is a format that stands in relative opposition to TEI. Since TEI can be reduced to XML[3], which is arguably a very strong format across many kinds of computing, it is no wonder that an XML based format would be a natural choice for marking up texts. However, JSON can trace its roots back to Javascript and, ultimately, conventions used by the entire C-family of programming languages.[4] In this, JSON is arguably more universal than XML. via Strange Bedfellows
- Unfortunately, XML is not well suited to data-interchange, much as a wrench is not well-suited to driving nails. It carries a lot of baggage, and it doesn’t match the data model of most programming languages. When most programmers saw XML for the first time, they were shocked at how ugly and inefficient it was. It turns out that that first reaction was the correct one. There is another text notation that has all of the advantages of XML, but is much better suited to data-interchange. That notation is JSON. via JSON.org
Yet, all of the DH projects I found were done specifically using JSON alongside XML, rather than as an alternative to:

That Godwin/Wollstonecraft/Shelley family sure could write a damn good novel.
I’ve also noticed both in the DH Methods class and in Lev Manovich’s Big Data class I am having to use java applets for necessary software (Mondrian and now XSLT processors). I’d like to talk more about Java, though I do not get the impression that it is something I should be diving into just because it runs specific applets that I need to do other things.
One final thought: I found THIS MESSAGEBOARD discussing the possibility of an “XSLT Zen Garden” which I would love to see. In fact I’d love to see a TON of Zen gardens, the CSS Zen Garden was fairly responsible for me learning CSS almost a decade ago. Definitely check that out if you haven’t seen it. Would such a thing be possible with XSLT?